
Постановка проблемы
Известно, что «среднестатистический житель планеты проводит онлайн почти 7 ч ежедневно», а граждане России входят в число людей, которые наиболее активно используют интернет, проводя в онлайн-среде в среднем 7 ч 17 мин в день1.
Неудивительно, что исследования цифровой среды и новых форм коммуникации с каждым днем становятся все более актуальными.
Цифровые сети являются одним из основных видов передачи информации в современном обществе [Capurro 2009]. Они используются не только для межличностной коммуникации и социализации, но и для обмена мнениями и выражения собственного мнения, политической агитации, формирования общественного мнения, в образовательных целях и пр. Цифровизация проникает во все сферы социальной жизни, подвергая модификации коммуникационную среду и сами процессы коммуникации. Подобного рода цифровые коммуникации находят свое отражение в новых жанрах общения и новых моделях текста.
Понятие «медиатекст» стало активно использоваться в научной среде в 1990‑е годы, когда ученые начали уделять особое внимание изучению специфики функционирования языка в сфере массовой информации и единиц медиапотока. Особый вклад в развитие теории языка СМИ внесли такие отечественные ученые, как С. И. Бернштейн, Г. Я. Солганик, Ю. В. Рождественский, Д. Н. Шмелев, В. Г. Костомаров, Б. В. Кривенко, И. П. Лысакова и др., а также зарубежные ученые, например Тён ван Дейк, Роберт Фаулер, Норман Фейерклаф, Алан Белл, Мартин Монтгомери и др.
Принципиальным отличием мультимодального текста от традиционного является интеграция письменного текста, визуальных изображений и звукового материала. В рамках традиционной лингвистики текст определяется как «результат целенаправленного речевого творчества, целостное речевое произведение», где основные единицы текста — это вербальные знаки. В семиотике «текст — это осмысленная последовательность знаков», т. е. единицами текста могут быть не только вербальные знаки, но и любые другие знаки, например видеоряд, музыкальный ряд, графические изображения и т. д. [Солганик 2005].
В данной работе вслед за М. А. Пильгун мы рассматриваем медиатекст как «синкретическое единство вербальных и невербальных компонентов, обладающее связностью и цельностью, имеющее определенную целенаправленность и прагматическую установку» [Пильгун 2015].
Упомянутые семантико-семиотические особенности медиатекста способствуют изменению структуры сообщения, а также его восприятия. Массовый характер медиатекста изменяет и институт авторства, традиционный автор заменяется творческим сознанием потребителя. Виртуализация информационного пространства и информационно-коммуникационные технологии обусловили появление новых коммуникативных форм, которые существуют безотносительно к агентам и адресантам [Пильгун 2015].
Очевидно, что такая качественно новая форма социального взаимодействия требует выработки определенных регулятивных норм и принципов. Такую функцию призван осуществлять цифровой этикет.
Термин «цифровой этикет» появился во время становления третьего поколения Всемирной глобальной паутины (Web 3.0) и рассматривается как «нормативноэтический регулятор коммуникативного взаимодействия в сети при помощи всех форм этикетной коммуникации: письменной, поведенческой и речевой и представляет собой более широкое понятие, чем сетевой этикет» [Мамина, Царева 2018]. В свою очередь, сетевой этикет, или нетикет, был одной из первых форм организации взаимоотношений в сети, которая сформировалась в эпоху Web 1.0 и претерпела качественные изменения вместе с развитием Web 2.0.
Проблематика цифрового этикета находится в сфере внимания ученых разных специальностей: лингвистов, политологов, социологов, культурологов, психологов и др. Многочисленные исследования последних лет показывают междисциплинарный характер нового этикета, а также разнообразие его содержательных характеристик.
Актуальность анализа тематики цифрового этикета подчеркивается многочисленными публикациями последних лет. Согласно работе М. Ашок, где проводится систематический обзор литературы, посвященной цифровым технологиям, самые частотные лексемы 59 статей из 43 различных журналов следующие: данные, этика, технология, системы, изучающий, информирует, социально, алгоритмы и др. (рис. 1).

На данный момент в научной литературе применяется большое количество терминологических синонимов к понятию «цифровой этикет». Наиболее часто употребляемые — информационная этика, этика больших данных, этика алгоритмов, этика цифровых медиа, этика цифровой журналистики, этика геоблокировки [Schmücker 2022], этика искусственного интеллекта, киберэтика, этика данных, сетевой этикет, компьютерная этика [Schultz, Seele 2022]. Ниже приводятся дефиниции терминов, связанных с этическими вопросами в цифровой среде (табл. 1).
Таблица 1. Цифровой этикет и его терминологические синонимы
| Термин | Определение |
| Информационная этика | «В узком смысле это все, что касается воздействия цифровых технологий на общество и на окружающую среду в целом, а также решения этических проблем, связанных с функционированием онлайновых СМИ (этика цифровых СМИ) в частности. Понятие информационной этики в широком смысле охватывает всю информационную и коммуникационную сферу, включая, но не ограничиваясь ими, цифровые средства массовой информации» [Каппуро 2010] |
| Этика больших данных | «Большие данные являются стимулом задуматься над вопросами этичности их использования и опасности нарушения основных гражданских, социальных, политических и юридических прав» [Mateosian 2013] |
| Этика алгоритмов | «С точки зрения алгоритмов самый главный вопрос в том, чтобы они были справедливы в принятии каких-либо решений и честны с пользователем»2 |
| Этика цифровых медиа | «Цифровая медиаэтика», или «этика цифровых медиа», — термин, введенный в журналистский и научный дискурс относительно недавно. В более широком смысле, цифровая медиаэтика, являясь последствием развития цифровых информационно-коммуникационных технологий, охватывает весь комплекс этических вопросов, возникающих в цифровой медиасреде» [Афанасьева 2014] |
| Этика геоблокировки | «Область этики, которая занимается вопросами конфликта потребительского поведения и конкретного рынка, а именно ограничение доступа к различному интернет контенту по территориальному признаку» [Zahrádka 2018] |
| Этика искусственного интеллекта | [Этика искусственного интеллекта] «является частью этики технологий, характерной для роботов и других искусственно интеллектуальных существ. Она обычно подразделяется на робоэтику, которая решает вопросы морального поведения людей при проектировании, конструировании, использовании и лечении искусственно разумных существ и машинную этику, которая затрагивает проблемы морального поведения искусственных моральных агентов»3 |
| Компьютерная этика | «Анализ природы и социального воздействия компьютерной технологии в сочетании с соответствующими формулировками этического оправдания технологии» [Галинская 2001] |
| Киберэтика | «Киберэтика имеет дело с будущими компьютерными технологиями, с качеством жизни, с этическими и социальными проблемами, связанными с киберпространством и обществом всемирной компьютерной среды» [Галинская 2001] |
| Интернет-этикет | «Модели поведения личности с установками, направленными на соблюдение правил поведения в коммуникативном пространстве…» Интернет-этика «получила название нетикет (от англ. Net + Etiquette) — свод правил, советов и рекомендаций по поведению и общению в сети Интернет» [Мосейко 2019] |
Таблица наглядно демонстрирует, что между терминами нет четкого разграничения по изучаемому предмету и области применения. Однако некоторые термины все же отличаются ключевыми характеристиками, например этика геоблокировки занимается исключительно вопросами этичности локализации интернет-контента.
Представленный ниже график позволяет проследить, как менялась частотность употребления терминов в англоязычной литературе. На сегодняшний день самые употребляемые слова — это информационная этика (information ethics), компьютерная этика (computer ethics) и цифровой этикет (digital ethics). При этом начиная с 2015 г. наблюдается стремительный рост частоты употребления термина цифровой этикет (digital ethics) (рис. 2).
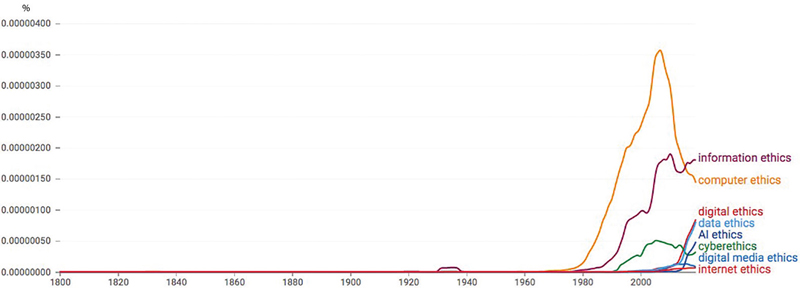
Источник: Google Books Ngram Viewer.
Из перечисленных выше вариантов терминов в русскоязычной литературе сервис Google Books Ngram Viewer обнаружил только сетевой этикет, компьютерная этика, информационная этика (рис. 3). Самым распространенным является понятие сетевого этикета.
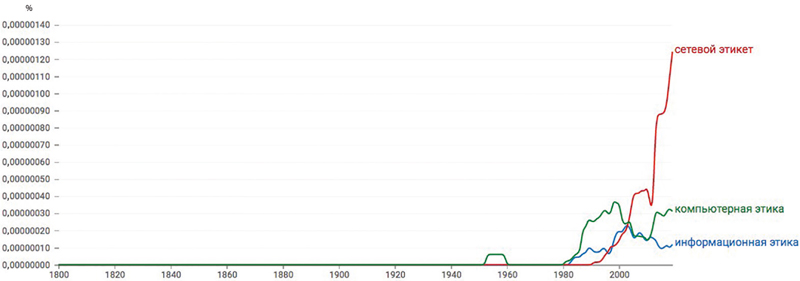
Источник: Google Books Ngram Viewer.
Очевидно, что цифровой этикет сегодня — это широкое понятие, которое включает в себя более специализированные области этики, такие как информационная этика, этика больших данных, этика алгоритмов, этика цифровых медиа, этика цифровой журналистики, этика геоблокировки, этика искусственного интеллекта и др.
Учитывая данную специфику, неудивительно, что в настоящее время существует большое количество литературы о правилах коммуникации в виртуальном пространстве. Ольга Лукинова в книге «Цифровой этикет. Как не бесить друг друга в сети» отмечает, что «цифровой этикет помогает людям избежать неловкостей в общении и предлагает готовые конструкции, как вести себя в разных ситуациях в Сети», а также предлагает практические рекомендации [Лукинова 2020]. Данное определение цифрового этикета подтверждается в научных публикациях отечественных авторов. Например, Л. Р. Дускаева в исследовании речевого этикета в онлайн-сообществах указывает на то, что «существующие правила в онлайн-сообществах направлены на то, чтобы сделать общение эмоционально комфортным, нейтрализовать агрессию, поощрять пользователей демонстрировать вежливость и проявлять внимание друг к другу» [Duskaeva 2020]. Изучая этикетные особенности коммуникации в интернет-сообществах, О. В. Золтнер делает вывод о том, что в онлайн коммуникации происходит «стилистический сдвиг», то есть традиционные правила речевых регистров в онлайн-среде не работают. Фамильярные, подчеркнуто-вежливые и грубые регистры русского литературного языка превращаются в нейтральные и дружески-неофициальные [Золтнер, Шабурова 2017].
Консультативная группа по этике, учрежденная Европейским надзорным органом по защите данных с целью изучения взаимоотношения между правами человека, технологиями, рынками и бизнес-моделями в XXI в., в опубликованном в 2018 г. отчете анализирует трудности перехода в цифровой формат жизни. Специалисты подчеркивают, что необходимо переосмысление фундаментальных ценностей в обществе, которое управляется большими данными и в котором есть уязвимые группы. Такого рода задача требует диалога между законодателями и экспертами по защите данных, касающихся вопросов сохранения неприкосновенности частной жизни и морально-этических проблем защиты данных [Burgess et al. 2018].
Круг актуальных вопросов цифровой этики также широк и разнообразен. Ученые исследуют проблемы дискриминации различных групп населения в процессе использования программы распознавания лиц [Khalil et al. 2020], случаи незаконного получения персональных данных пользователей Facebook* компанией Cambridge Analytica [Venturini, Rogers 2019], использование социальных медиа и Twitter-ботов в период Брексита и выборов президента США в 2016 г. [Gorodnichenko, Pham, Talavera 2021] и пр.
В рамках нашего исследования будем понимать цифровой этикет как продолжение речевого этикета, направленного на нейтрализацию агрессии по отношению к уязвимым членам общества в онлайн-среде.
Описание методики исследования
Целью настоящего исследования является анализ и последующее сравнение особенностей цифрового этикета в русском и английском языке на примере текстов социальных медиа, посвященных теме миграции и мигрантам.
В качестве материала были использованы данные социальных медиа объемом 8 478 629 знаков («ВКонтакте», «Одноклассники», YouTube и др.). Дата сбора: с 11.11.2019 по 11.12.2019. Для анализа англоязычных медиатекстов были собраны данные iWeb по входному слову migrant. Корпус iWeb содержит 14 млрд слов из Всемирной паутины и примерно 95 000 веб-сайтов, что позволяет сделать большой охват аудитории и проанализировать разнообразный контент, включая данные социальных сетей, форумов, чатов, постов и пр. Общий объем проанализированных англоязычных интернет-сообщений 1 185 200 знаков.
В ходе работы были использованы следующие методы: сентимент-анализ для выявления тональности сообщения [Agarwal et al. 2020; Poria, Hussain, Cambria 2018; Bing 2012; Solovyev, Antonova, Pazelskaya 2012], анализ лексических ассоциаций для определения интенций автора и оценочной парадигмы текста [Vivas et al. 2019; Kharlamov, Pilgun 2020; Nelson, McEvoy, Schreiber 2004].
Сентимент-анализ представляет собой выявление тональности текста с помощью фиксации эмотивной лексики. Такой метод контент-анализа может быть осуществлен с помощью автоматических программ текстового анализа, которые построены на основе тональных словарей, теоретико-графовых моделей или алгоритмов машинного обучения. Тональность текста также может быть определена с помощью лингвистической экспертизы. Для наиболее эффективного анализа мы применили комбинацию указанных методов.
Анализ лексических ассоциаций позволяет определить интенции автора и выявить имплицитную информацию в сообщении. Для данного исследования была использована программа интеллектуального анализа текста TextAnalyst, с помощью которой мы выполнили ассоциативный поиск по запросу «мигрант».
Анализ материала и результаты исследования
Для анализа русскоязычных медиатекстов была использована Eureka Engine — система выявления тональности сообщений, разработанная Brand Analytics. Программа базируется на статистическом алгоритме условных случайных полей CRF с использованием тональных словарей. В качестве входных данных используются последовательности лексем, затем алгоритм вычисляет вероятности возможных последовательностей меток и выбирает максимально вероятную.
В результате 29 % сообщений были определены как негативные, 66 % — нейтральные и 5 % — положительные. Приведем примеры.
Мигранты-разбойники были задержаны полицией в Москве.
Он сделал Москву безразмерной для мигрантов всех мастей!
В настоящее время в Москву и другие города России переселяются миллионы мигрантов (азербайджанцев, армян, афганцев, китайцев, вьетнамцев и т. д.).
Теперь гости Москвы из Средней Азии планируют собраться на смотровой площадке Воробьевых гор у главного здания МГУ — там, где любит проводить Новый год молодежь. Отметим, что в ряде регионов Таджикистана, Узбекистана и Киргизии действуют запреты на отмечание «кафирского» Нового года.
Ленинградская область по количеству мигрантов занимает четвертое место в России, что накладывает свой отпечаток на этноконфессиональную обстановку. Большое внимание в Ленинградской области, по словам Евгения Сиренького, уделяется адаптации мигрантов.
Поколение бомжей. Что ждет понаехавших в мегаполисы. В Москве и Петербурге люди десятилетиями снимают квартиры. Не потому, что хотят свободы перемещений и прочих хипстерских наворотов. Просто купить не могут.
Все текстовые данные были разделены на три блока (негативный, позитивный и нейтральный) и проанализированы с помощью программы автоматического анализа текста TextAnalyst.
Построенная семантическая сеть выявила смысловой портрет анализируемых данных и определила основные темы: адаптация детей мигрантов, обучение русскому языку приезжих, сохранение их национального языка, регуляция трудовой деятельности мигрантов на территории России.
Нейтральные тексты фиксируют тему ассимиляции мигрантов и их детей посредством обучения приезжих культуре и языку этнического большинства. Следует отметить, что в данном блоке сообщений были обнаружены лексемы с отрицательной семантикой, разговорно-сниженная лексика, слова с негативной социальной коннотацией, что влияет на восприятие текста и позволяет его отнести к группе негативных.
Сообщения, выражающие позитивную оценку, отображают тему интеграции мигрантов и развитие толерантного отношения к приезжим.
Негативные сообщения включают лексические единицы с определенным ассоциативным компонентом, синтаксические конструкции и понятия, функционирующие как стереотипы, которые способствуют формированию отрицательной тональности.
Для анализа направленности англоязычного медитекста были собраны данные iWeb по входному слову migrant. В качестве инструмента исследования использовалась программа автоматического текстового анализа LIWC (Linguistic Inquiry and Word Count). Данная программа определила общий эмоциональный тон сообщений как низкий, то есть большинство сообщений являются негативными. Выявленная эмотивная лексика указывает на отрицательные категории эмоций, в частности враждебность (рис. 4). Эмотивная лексика составляет 3,17 %, фиксируются негативные эмоции: беспокойство (0,30 %), злость (0,45 %), грусть (0,28 %). Высокий процент «воздействия» сообщений (72,83 %) выявляет степень убежденности автора, что подтверждается высоким процентом «аналитического мышления» (96,39 %). Например.
But some kinds of work are not regulated. Children of migrant workers, for example, have no legal protection.
Angie. Now you have gone ahead and green-lighted an unlimited mass invasion of unscreened migrant hordes from the Middle East and Africa.
It is safe to say, then, that through the prism of the unrestricted movement of EU nationals into the UK, immigration was and is a cause of anxiety for many.
…whats happening is that the UK citizens are sick of being taken for fools, are sick of taking in people who don’t share their values and have no intention of but more importantly want the UK to adapt to them.
…real refugees take refuge in the first country they arrive in… these are financial migrants,, trying to get on the uk gravy train… the UK govt badly misjudged the feelings of its population over the farce that was brexit, the uk are leaving because the countries population has simply had enough of mass unchecked migration to the UK by millions… letting in these 25 yr old children just compound the issues…
Проведенный анализ лексических ассоциаций позволил выявить имплицитную информацию данных сообщений. Необходимо заметить, что в англоязычных медиатекстах нами не было обнаружено сообщений с позитивной направленностью, вместо этого были выявлены сообщения, выражающие эмпатию.
Негативные коннотативные характеристики сообщениям придают: замена стилистически нейтрального слова маркированным синонимом, лексемы с отрицательной семантикой, отсылка к негативным событиям и использование понятий с определенным оценочным компонентом и тех, которые транслируют этнические стереотипы.
Выводы
Результаты проведенного анализа русских и англоязычных медиатекстов, посвященных мигрантам, показывают, что количество негативных сообщений в социальных медиа о мигрантах превышает позитивные сообщения.
В обоих типах сообщений была обнаружена пренебрежительная разговорносниженная лексика, экспрессивные синтаксические конструкции, полисемия со значением неодобрения. В отличие от английских, среди русскоязычных сообщений были обнаружены тексты с позитивной направленностью. В англоязычных отмечены сообщения, выражающие солидарность с мигрантами в связи с их уязвимым положением в обществе.
Таким образом, дискурс о мигрантах в русскоязычных и англоязычных социальных медиа отличается политематичностью. С одной стороны, в цифровой среде присутствуют положительные сообщения о социокультурной адаптации и интеграции мигрантов, с другой — вопросы стереотипизации по этническому и религиозному признаку все еще остаются актуальными.